Why concurrency is hard, before any code
Most bugs in concurrent systems come from a small number of misconceptions about what the runtime actually guarantees. We'll start at the bottom and build up.
What is a thread?
A thread is an independent sequence of instructions executing within a process. Modern services run dozens of threads at once: HTTP request handlers, scheduled jobs, message-queue consumers, garbage collection. Each thread has its own stack (function-call history, local variables) but shares the heap (objects, database connections, caches) with other threads in the same process.
The OS scheduler decides which threads run on which CPU cores at any moment. From outside one thread's point of view, another thread can interrupt at any point — between any two instructions, mid-method, mid-loop. There's no guarantee that anything you do happens "in one go" unless you explicitly arrange for that.
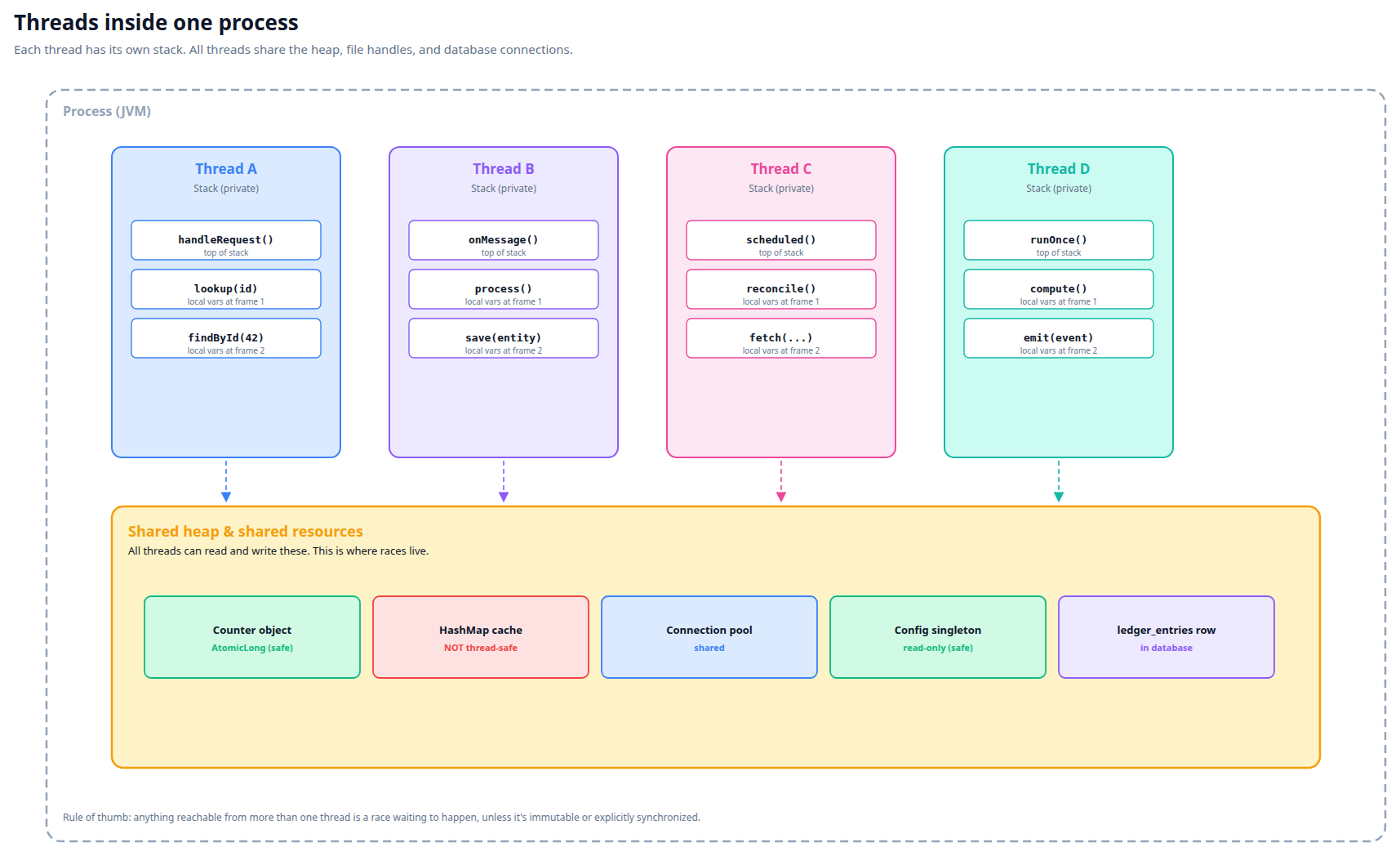
Each thread carries its own private stack — local variables, call history. Everything else (heap objects, connection pools, database rows) is shared. The shared layer is where every race lives.
Concurrency vs. parallelism
Concurrency
Multiple tasks making progress over the same time window. They may take turns on a single CPU core. The interleaving is decided by the scheduler.
Parallelism
Multiple tasks executing at the same instant on different CPU cores. Parallelism is one way to achieve concurrency; it's not the only one.
For race conditions, the distinction barely matters: even on a single-core machine, the scheduler can switch between threads at any instruction boundary, so a race that's possible in parallel is also possible in interleaved single-core execution.
Shared state — the source of all concurrent bugs
If two threads only touch their own local variables, nothing can go wrong. The trouble starts when both threads read or write the same memory (or the same database row, or the same file, or the same external system).
Three increasingly painful flavors:
| Pattern | Example | Risk |
|---|---|---|
| Read-only sharing | Both threads read a config that nobody mutates. | Safe. |
| One writer, many readers | One thread updates a counter; others display it. | Risky if the read is non-atomic (e.g., reading a 64-bit value on a 32-bit JVM, or reading a cluster of related fields). |
| Multiple writers | Two threads both decide whether to insert a row, based on a count. | This is where the worked-example bug in tab 8 lives. "Check, then act" is a classic shape. |
The illusion of "instant" operations
It's tempting to write code as if each statement happens in a single, indivisible moment. It doesn't. Consider:
val x = sharedCounter
sharedCounter = x + 1
That's two memory operations. Between them, another thread can read and increment sharedCounter. Result: two threads each thought they incremented the counter, but the counter only went up once.
Even sharedCounter++ is not atomic. It compiles to load → add → store — three steps that can be interrupted between any of them.

Both threads LOAD 100, both compute 101, both STORE. The second STORE just overwrites the first with the same value. Two "increments", one actual increment.
What "atomic" actually means
An atomic operation is one that, from any other thread's perspective, either has happened completely or hasn't happened at all. Never partway. Atomic operations are the building blocks for safe concurrent code.
The JVM gives you a few atomic primitives:
AtomicInteger,AtomicLong— atomic integers with operations likeincrementAndGet,compareAndSetAtomicReference<T>— atomic pointersvolatile— atomic reads and writes (but not compound operations likei++)- Locks (Java's
synchronized,ReentrantLock) — serialize access to a section of code
The database layer has its own atomicity guarantees, expressed via transactions — we'll get to that in tab 3.
Events arrive "at the same time" more often than you think
Naive intuition: events for the same logical thing usually arrive in order, well-separated in time. Reality:
- Stripe sends two webhooks for one payment (PaymentIntent succeeded, then Charge succeeded). They can arrive within milliseconds.
- SQS visibility timeout expiry can cause the same message to be delivered to two consumers.
- A user double-clicks a button. Two HTTP requests fire. Both reach your service.
- An external service's retry-on-failure can produce duplicate messages 30 seconds apart.
- A scheduled job and a manual trigger both fire at the same second.
Any of these creates concurrent operations on the same shared state. If your code path doesn't handle them, you have a latent race.
The key mental shift: assume any operation can happen multiple times, in unpredictable order, with arbitrary delays between steps. Your code must produce a sensible result regardless. That's what idempotency (tab 4) and proper isolation (tab 3) are for.
The taxonomy of race conditions
"Race condition" is a generic term. There are several distinct shapes, each with its own diagnostic and fix. Recognizing the shape helps you reach for the right tool.
1. Time of check / time of use (TOCTOU)
The classic. Code asks "does X exist?" and then "if not, create X." Between the check and the create, somebody else creates X. Both creators succeed. This is the shape we'll dissect in tab 8.
if (!fileExists("config.json")) {
createFile("config.json")
}
// Two threads can both reach createFile if both observe "doesn't exist."
General fix: collapse the check and the use into a single atomic operation. In the database, that's a unique constraint plus an "insert or update" pattern. In files, that's O_CREAT | O_EXCL. In code, that's a lock around the whole sequence.
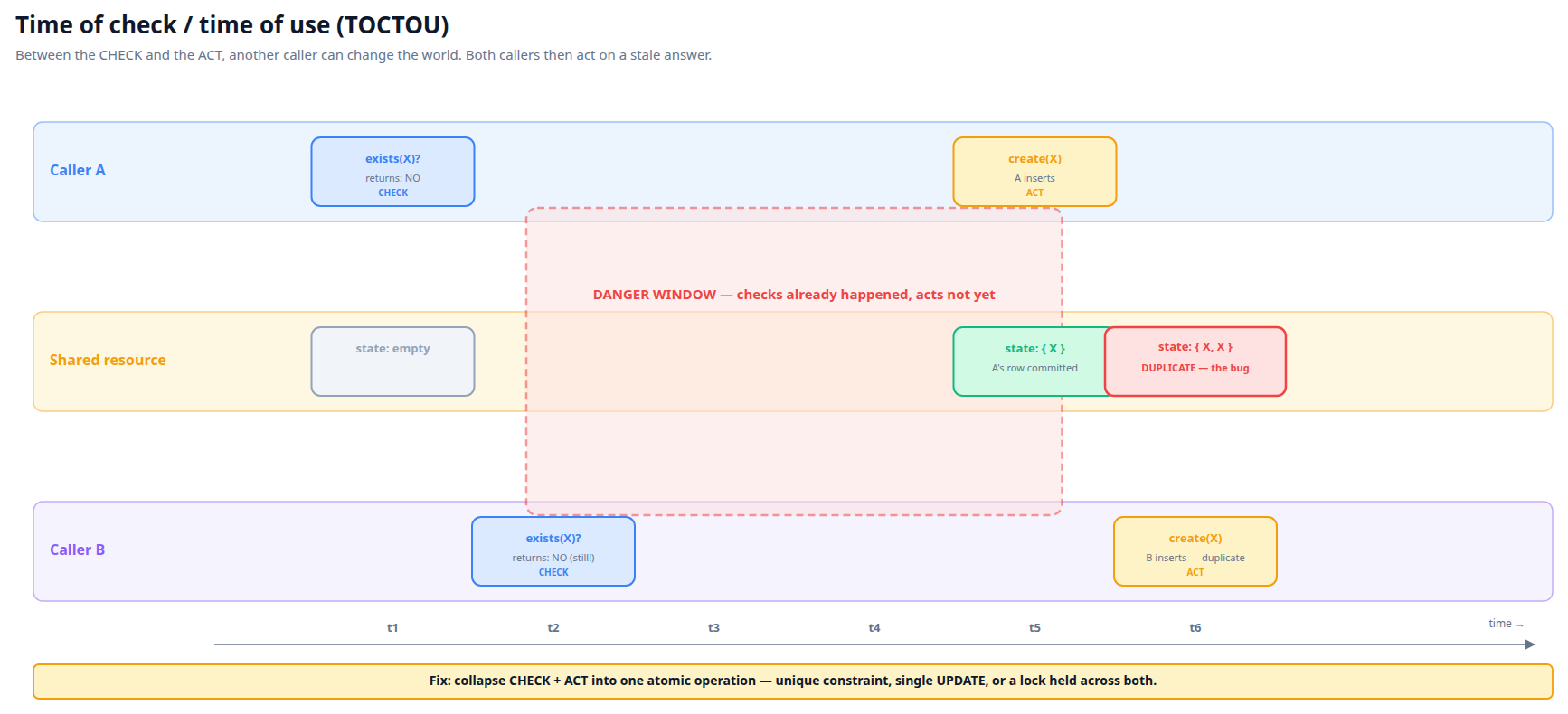
Both callers' checks return NO because the danger window opened between them. By the time either acts, the answer to the check is already stale — but they don't know that.
2. Lost update
Two threads both read the same value, both compute a new value based on what they read, both write back. One of the writes overwrites the other.
// Thread A: // Thread B:
val balance = account.balance val balance = account.balance
account.balance = balance + 50 account.balance = balance + 100
// If both read 200, A writes 250, B writes 300. The +50 is lost.
Fix: pessimistic lock (SELECT FOR UPDATE), optimistic lock (@Version), or a single atomic update statement (UPDATE ... SET balance = balance + 50).
3. Dirty read
Thread A modifies a row in an uncommitted transaction; Thread B reads it; Thread A rolls back; Thread B made a decision based on data that no longer exists.
Most production databases (PostgreSQL, MySQL InnoDB) prevent dirty reads by default — they use READ COMMITTED isolation, which only shows committed data. Worth knowing the term so you can confidently say "we don't have this problem."
4. Non-repeatable read
Thread A reads a row twice within the same transaction. Between the reads, Thread B updates the row. A's two reads return different values, even though A didn't change anything.
Fix: REPEATABLE READ isolation, which gives Thread A a consistent snapshot for the whole transaction.
5. Phantom read
Thread A counts rows matching some predicate. Between counts, Thread B inserts a new row matching the predicate. A's second count is higher than the first.
Fix: SERIALIZABLE isolation, or predicate locks. Postgres handles this via Serializable Snapshot Isolation (SSI), which detects predicate-level conflicts and aborts one of the transactions.
6. Write skew
Two transactions read overlapping rows, then each writes a different row. Each transaction would have been valid alone, but together they violate an invariant.
Classic example: an on-call schedule that requires "at least one doctor on duty." Two doctors both check "are there other doctors on duty?", see "yes" (they see each other), and both go off duty. Now nobody is on duty. Read-committed and even repeatable-read miss this — only SERIALIZABLE catches it.
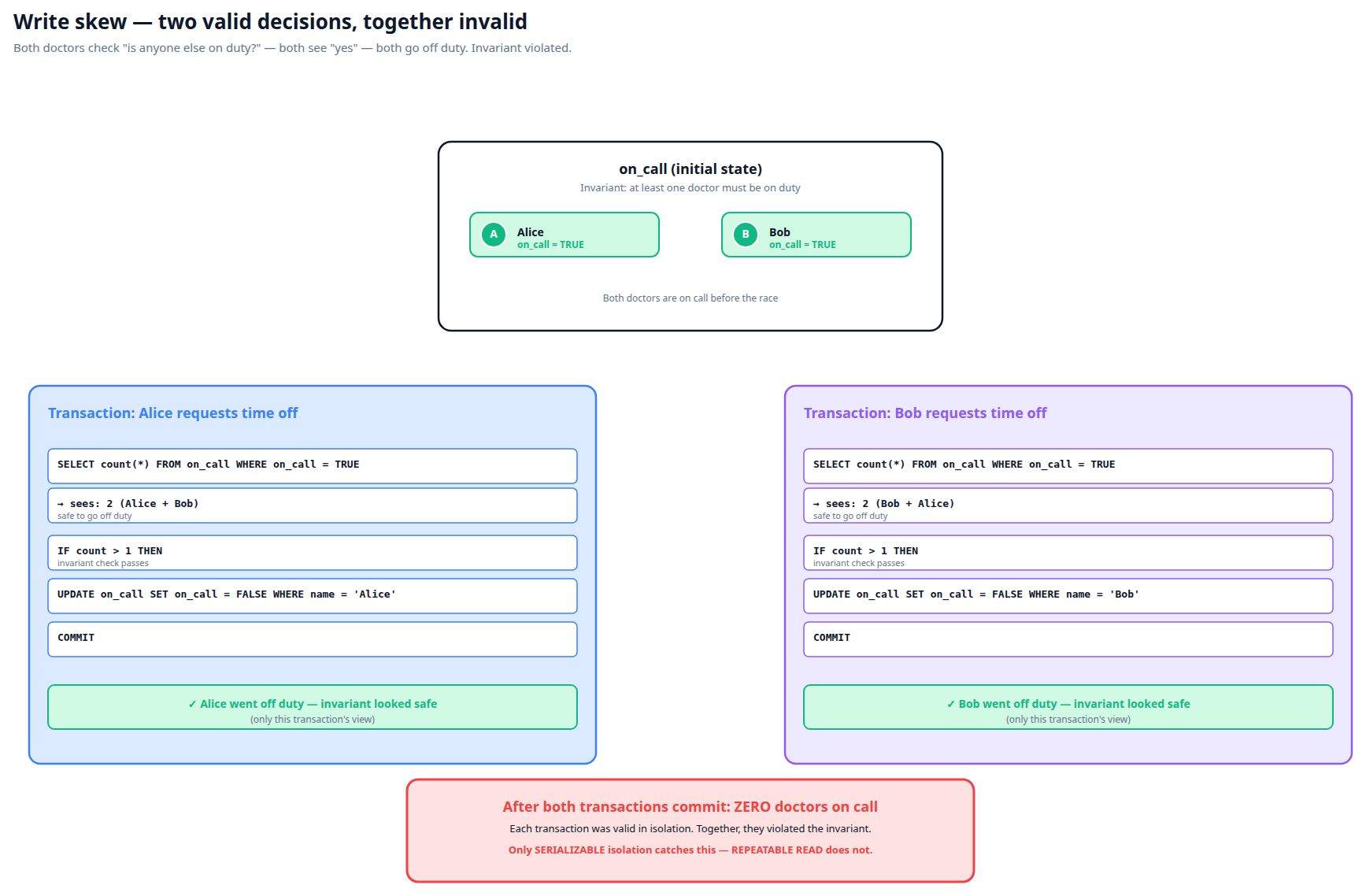
Each transaction is provably correct in isolation — the invariant check passes for each. The conflict isn't on the same row but on the predicate "how many are on duty". SERIALIZABLE detects this; nothing weaker does.
How the duplicate-row race maps onto this taxonomy
It's a TOCTOU race specifically. Two workers run "find existing row" (the check), see empty, then "INSERT new row" (the use). Between check and use, the other worker also checks and sees empty. Both INSERT. Two rows.
The fix space for TOCTOU: serialize the check-act sequence (a lock), make the act atomic at the database (a unique constraint), or both. We'll cover both in tabs 4–5.
Why "intermittent" doesn't mean "rare"
Race conditions are timing-dependent. The same code under different load can fire 50% of the time or 0.001% of the time. The bug exists either way. Production load can suddenly multiply the rate when:
- You upgrade infrastructure that changes thread scheduling (e.g., a Spring Boot upgrade that increases listener concurrency).
- You scale up replicas, increasing parallel processing of the same shared state.
- Traffic patterns change — an external service starts batching events that used to come in spread out.
- A new code path adds a previously-absent concurrent caller.
"It worked fine for years" is not evidence of correctness. It's evidence of luck.
How databases prevent (some) races: isolation levels
The database is one of the most useful concurrency tools you have, because it has decades of work on serialization built in. But to use it correctly, you have to understand what it actually guarantees.
ACID, in two sentences
A database transaction is supposed to be Atomic (all-or-nothing), Consistent (preserves invariants the schema says it must preserve), Isolated (one transaction's effects shouldn't bleed into another's view of the world), and Durable (committed data survives crashes). The "I" is the one most relevant to races, and it's the one databases tune via isolation levels.
The four standard isolation levels
| Level | Prevents | Doesn't prevent | Cost |
|---|---|---|---|
| READ UNCOMMITTED | (Almost nothing) | Dirty reads, lost updates, everything | Lowest. Postgres doesn't even support this — its lowest is READ COMMITTED. |
| READ COMMITTED | Dirty reads | Non-repeatable reads, phantoms, lost updates, write skew | Postgres default. Cheap. |
| REPEATABLE READ | Dirty reads, non-repeatable reads, lost updates* | Phantoms (in standard SQL), write skew | Snapshot of the database at txn start. Postgres calls this "snapshot isolation." |
| SERIALIZABLE | All of the above, plus phantoms and write skew | Nothing | Highest. Postgres uses Serializable Snapshot Isolation (SSI) — detects conflicts and retries. |
* Postgres's REPEATABLE READ raises an error on conflicting writes; you have to handle the retry.
The default — READ COMMITTED — is what fires our race
PostgreSQL's default isolation level is READ COMMITTED. Under this level:
- Each statement (each individual SELECT, UPDATE, INSERT) sees only data committed before that statement started.
- Your transaction may see different data on consecutive SELECTs of the same row, if another transaction committed in between.
- You don't see other in-flight transactions' uncommitted changes.
That last point is exactly what enables the duplicate-row race. Worker A's INSERT is in flight but uncommitted. Worker B's SELECT cannot see it. So B's SELECT returns empty. B decides to INSERT too.
What if we used SERIALIZABLE instead?
You could. Postgres's SERIALIZABLE detects this kind of conflict and fails one of the transactions with could not serialize access due to .... You catch the error and retry. The race becomes invisible to your application logic.
Why we don't usually do this:
- Performance: SERIALIZABLE has overhead. For high-traffic tables it can be measurable.
- Application complexity: every transaction must be retry-safe, because any of them can be aborted at commit time.
- You need to enable it deliberately — Spring's
@Transactional(isolation = Isolation.SERIALIZABLE).
For most applications, READ COMMITTED + careful use of unique constraints, locks, and idempotent patterns is the right balance.
Snapshot isolation in pictures
Under snapshot isolation (REPEATABLE READ), each transaction sees a frozen view of the database from the moment it began. Concurrent transactions don't see each other's writes until commit.
Two important Postgres concepts
MVCC — multi-version concurrency control
Postgres doesn't lock rows for reads. Instead, it keeps multiple versions of each row, tagged with the transaction that wrote them. A SELECT picks the version visible to the current transaction's snapshot. This is why concurrent reads don't block writes (or each other).
Predicate locks — the SERIALIZABLE secret
SERIALIZABLE on Postgres uses Serializable Snapshot Isolation. It tracks read sets and write sets of in-flight transactions. If two transactions' reads and writes can be shown to conflict in a way that no serial ordering would have produced, one is aborted at commit time.
Practically: you write your code as if you're the only one running, and the database catches conflicts via retry. Cleaner than locks, but you have to handle SQLState 40001 serialization errors.
Unique constraints — the lightweight serializer
You don't always need higher isolation. Often the rule you want to enforce is "no two rows with the same X" — and that's a unique constraint, which Postgres enforces atomically at INSERT time, regardless of isolation level.
Two transactions both INSERT a row with the same value of a unique-constrained column? One succeeds, the other fails with duplicate key value violates unique constraint .... Catch and recover. The race becomes a known, handleable error.
This is the canonical shape for any "find or create" against a uniquely-keyed row. Discussed more in tab 4 (idempotency) and tab 7 (Spring patterns).
Idempotency — making operations safe to repeat
In any system that delivers messages "at least once" — which means basically every queue, every webhook, every microservice — you will receive duplicate events. Your code must handle them. Idempotency is the property that doing an operation N times has the same effect as doing it once.
Delivery semantics
| Semantic | Means | What you must do |
|---|---|---|
| At-most-once | Message may not be delivered at all (sender doesn't retry). | Tolerate loss. Use only when missing data is acceptable. |
| At-least-once | Message will arrive, possibly multiple times. | Make handler idempotent. This is the common case (SQS, Kafka, webhooks). |
| Exactly-once | Marketing language. Doesn't truly exist end-to-end. | Don't trust the label; build idempotency anyway. |
"Exactly-once" appears in some systems (Kafka transactions, SQS FIFO queues) but only within their boundary. The moment you bridge to another system — your database, an external API — you're back to at-least-once. Always assume at-least-once and design accordingly.
Three idempotency patterns
Pattern 1: idempotency key (client-supplied)
The client (or upstream system) sends a unique key per logical operation. Your server stores processed keys. On retry, you recognize the key and short-circuit.
POST /payments
Idempotency-Key: 2c4f1d80-3b6a-4d2e-bc15-9f8e8a3a4e5d
{ "amount": 100, "currency": "USD" }
Stripe uses this pattern (and exposes it). Internally, Stripe stores the key + the response for ~24 hours. If you retry with the same key, you get the cached response — no duplicate charge.
Pattern 2: natural idempotency from a unique constraint
Define what makes a row unique in business terms (e.g., "one settlement per (reservation, payment) pair"). Add a unique constraint. INSERT idempotently:
// Try to insert; if a duplicate exists, recover
return repo.save(newRow)
.onErrorResume(DataIntegrityViolationException::class.java) {
repo.findByBusinessKey(newRow.businessKey)
}
This is the canonical idempotent-insert pattern for any "find-or-create" on a uniquely-keyed row. Once you've seen it once, you'll see it everywhere.
Pattern 3: idempotent state transitions
Some operations are naturally idempotent if you check current state first.
fun markAsCompleted(id: Long): Mono<Unit> {
return repo.findById(id)
.flatMap { entity ->
if (entity.status == COMPLETED) {
Mono.empty() // already done; skip
} else {
repo.save(entity.copy(status = COMPLETED))
}
}
}
Watch out: this pattern still has the TOCTOU shape. Concurrent calls can both observe "not completed" and both transition. Need to combine with a unique constraint, optimistic locking (@Version), or pessimistic locking (SELECT FOR UPDATE).
The retry semantics that confuse people
Common mistake: "Our message queue retries failed handlers automatically, so we're safe." Retrying a non-idempotent handler is exactly how you get duplicates. The queue is doing what it was designed to do — making sure your handler runs at least once. The handler must do the rest.
Idempotency at every layer
A real system has many layers: HTTP request, message queue, application logic, database. Each one needs its own idempotency strategy. You can't push it down to one layer and call it a day.
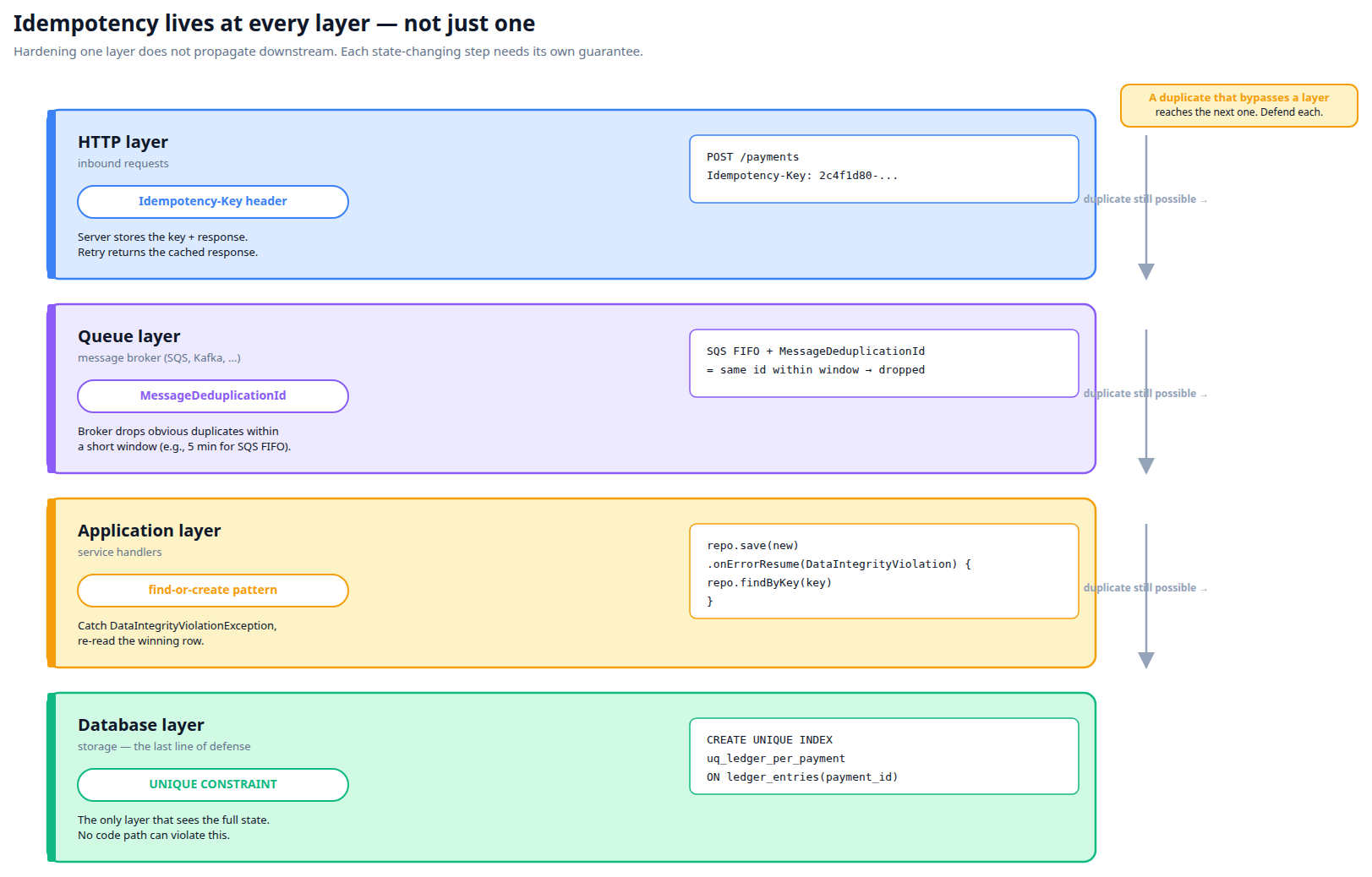
A duplicate that bypasses one layer reaches the next. The database constraint is the last line of defense — the only layer with full visibility into existing state.
- HTTP layer: idempotency keys for POSTs that mutate state.
- Queue layer: deduplication windows (e.g., SQS
MessageDeduplicationId) catch obvious duplicates within a short window. - Application layer: "find or create" patterns that handle duplicates from any source.
- Database layer: unique constraints as the last defense — the database is the only layer that has full visibility into the state.
A common failure mode: one layer is hardened (e.g. with a unique-constraint + recovery), but a downstream step has its own check-then-act with no protection. The race fires there instead. Idempotency doesn't propagate downstream — every state-changing step needs its own guarantee.
Idempotency vs. determinism
Idempotency means N times = 1 time. It does not mean the operation always produces the same output. UPDATE counter SET value = NOW() is idempotent in the sense that running it many times leaves the counter in a valid state — but the value will differ each time. Distinguish "safe to repeat" from "produces the same result every time."
Locks, distributed coordination, and their pitfalls
When you can't make an operation idempotent at the data layer, you fall back to serialization via locks. Locks are blunt — they work, but they have failure modes the database constraint approach doesn't.
Lock taxonomy
| Type | Scope | How | Used for |
|---|---|---|---|
| Mutex | One thread at a time | synchronized, ReentrantLock, Mutex |
Serializing in-process access |
| Read-write lock | Many readers OR one writer | ReentrantReadWriteLock |
Read-heavy caches with rare writes |
| Semaphore | N permits | Semaphore(N) |
Bounded parallelism (e.g., max 5 concurrent API calls) |
| Optimistic lock | One winner per version | JPA @Version, CAS |
"Try to write; if version changed, retry" |
| Pessimistic DB lock | Per-row, transaction-scoped | SELECT FOR UPDATE |
Lost-update prevention on a known row |
| Postgres advisory lock | Application-defined key, session/txn-scoped | pg_advisory_xact_lock(hashtext('key')) |
Cross-replica serialization without new infrastructure |
| Distributed lock | Cross-process, cross-replica | Redis (Redlock), ZooKeeper, etcd, custom registry | Coordinating side-effects across replicas |
Lock scope: in-process vs. cross-process
The most important question when picking a lock: which units of execution need to be serialized?
- Threads in one JVM: a JVM lock (
ReentrantLock,synchronized, Spring'sLockRegistry) is enough. - Processes on the same machine: file locks, OS semaphores. Rare in modern services.
- Replicas across multiple machines: need a distributed lock, OR a database-level mechanism (advisory lock, unique constraint).
Picking distributed when you only need JVM-level pays unnecessary cost. Picking JVM when you need distributed leaves a silent gap.
Optimistic vs. pessimistic locking
Pessimistic
Acquire the lock before doing work. Block other workers. If you finish, release. Cost: contention, potential deadlocks, slow under load. Wins: simple semantics, predictable.
Example: SELECT * FROM x WHERE id = 1 FOR UPDATE — locks the row until your txn commits.
Optimistic
Don't lock. Read, do work, write conditionally on the state not having changed. If it changed, retry. Cost: retries under contention, complexity. Wins: high throughput when conflicts are rare.
Example: JPA's @Version column — UPDATE includes WHERE version = :original_version. If it didn't update any row, retry.
Distributed locking — the dragons
Distributed locks are surprisingly hard to get right. The famous Redlock controversy (Martin Kleppmann vs. Salvatore Sanfilippo) is worth knowing:
Redlock is a Redis-based distributed lock algorithm. It works in many cases. It can fail in specific failure modes — clock drift, network partitions — in ways that allow two clients to believe they hold the lock simultaneously. This is OK if you only use it for efficiency (preventing wasted work), but disastrous if you use it for correctness (preventing data corruption).
The remedy: fencing tokens. The lock issuer hands out monotonically-increasing tokens. The protected resource accepts writes only with tokens ≥ the highest seen. Even if two clients think they hold the lock, only the one with the higher token can write. Postgres advisory locks naturally avoid this because they're tied to the database connection state — but for Redis-style locks, fencing is essential for correctness use cases.
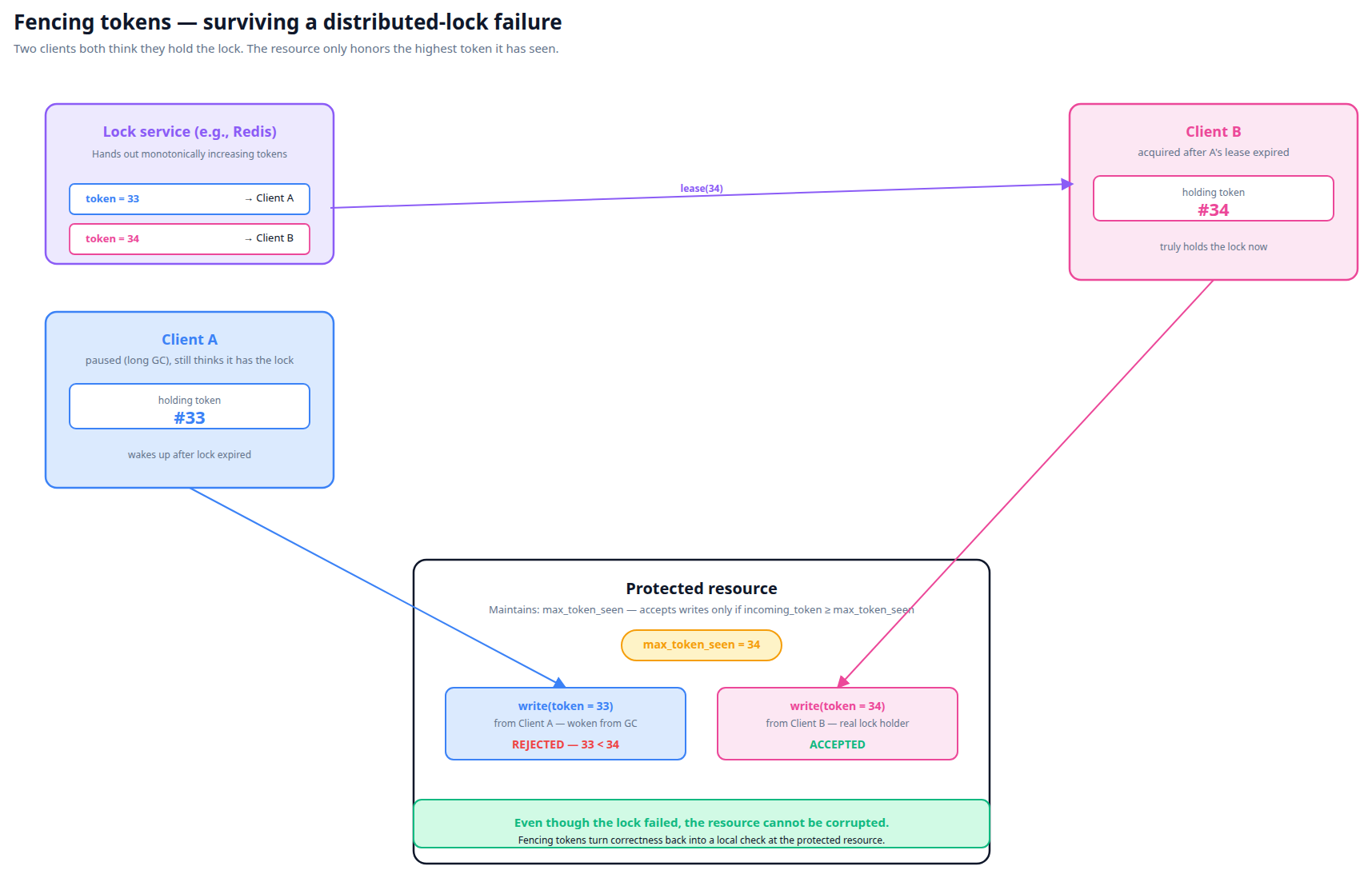
Even if the lock service hands two clients overlapping leases, the protected resource enforces correctness locally by remembering the highest token it has seen. The stale lock holder's write is refused.
Common lock pitfalls
Deadlock
Two threads each hold a lock the other needs. Neither can proceed. Prevention: always acquire locks in a consistent order.
Lock not released on error
If you don't use try-finally (or equivalent), an exception inside the locked section leaves the lock held forever. Always use:
lock.lock()
try {
// protected section
} finally {
lock.unlock()
}
Reactor's doFinally serves the same purpose for reactive chains.
Lock holder dies
If the process holding the lock crashes, who releases the lock? In-process: the JVM exit cleans up. Cross-process distributed lock: depends on whether the lock has a TTL. Postgres session-scoped advisory locks release when the connection closes.
Lock granularity wrong
Too coarse: you over-serialize and kill throughput (locking the whole listener instead of per-paymentId). Too fine: you miss part of the race (locking just the SELECT but not the INSERT). The right granularity is "exactly the resource being raced for."
When to lock and when not to
Decision order, in priority:
- Can you avoid sharing entirely? Partition the data so each worker owns its slice. Best.
- Can the database enforce the invariant? Unique constraint with conflict recovery. Often the right answer.
- Do you need a lock? Use the smallest scope that's correct: JVM lock if single-replica, advisory or distributed if multi-replica.
- Do you need a heavyweight distributed lock with fencing? Only if (1)–(3) don't apply, which is rare.
Concurrency in Reactor and Kotlin
Project Reactor (the reactive library Spring WebFlux uses) has its own concurrency model. It's powerful but has gotchas that don't exist in plain blocking Java.
Mono and Flux — declarations of work, not work itself
A Mono<T> represents a future computation that will produce 0 or 1 result. It doesn't run when constructed — it runs when somebody subscribes to it. This is the most important thing to internalize.
val mono = Mono.fromCallable {
println("ran")
42
}
// "ran" hasn't been printed.
mono.subscribe() // now "ran" is printed.
mono.subscribe() // now "ran" is printed AGAIN — every subscription re-runs the work.
For mutating operations, you typically want exactly one subscription. .block() subscribes and waits; the SQS listener pattern in our codebase does this at the boundary.
Schedulers — where does the work actually execute?
By default, Reactor operators run on whatever thread emits the upstream value. If your Mono chain starts on a Netty event-loop thread, all the operators run there too — unless you explicitly switch.
| Operator | Effect |
|---|---|
.subscribeOn(scheduler) | Where the WHOLE chain runs (the source of values runs there). Only the first subscribeOn in the chain wins. |
.publishOn(scheduler) | Switches threads from this point onwards. Multiple publishOns create thread hops. |
Common schedulers
Schedulers.parallel()— fixed-size pool sized to CPU count. For CPU-bound non-blocking work.Schedulers.boundedElastic()— large pool (cap × CPUs, default 10×) intended for blocking I/O. Use this when calling JDBC, file I/O, or any blocking operation from a Mono.Schedulers.single()— one thread shared across the JVM. Useful for serial-by-construction flows.- Custom:
Schedulers.fromExecutor(...). The codebase'sjdbcScheduleris one of these — a dedicated pool for JDBC calls.
The blocking-call trap
Calling a blocking operation from a Reactor thread (without switching schedulers) blocks the entire event loop. Symptoms: timeouts, tasks stuck in queue, throughput collapse. Reactor will sometimes detect this and throw BlockHound errors in tests, but production silently degrades.
The rule: any blocking call (JDBC, JPA save(), Thread.sleep(), file.read()) must run on boundedElastic or another blocking-friendly scheduler.
// WRONG — runs on the calling thread, possibly an event loop:
Mono.fromCallable { jpaRepo.save(entity) }
// RIGHT:
Mono.fromCallable { jpaRepo.save(entity) }
.subscribeOn(Schedulers.boundedElastic())
Our codebase wraps JDBC repositories with ReactiveRepositoryWrapper, which subscribes on jdbcScheduler internally — so callers don't think about it. But if you write your own JPA call inside a Mono, remember.
Concurrent Mono subscribers
If two threads each subscribe to the same Mono, the work runs twice. This is essential for retries (a retry resubscribes) but surprising if you assumed a Mono is "the result of running the work."
For deduplication of in-flight subscriptions, use .cache() — but understand it caches the result forever; second subscribers see the cached value, not new work.
Mono and locks — the right pattern
To lock around a Mono chain in Reactor:
fun <T> withLock(lock: Lock, work: () -> Mono<T>): Mono<T> {
return Mono.fromCallable { lock.lock(); true }
.subscribeOn(Schedulers.boundedElastic()) // lock.lock() blocks
.flatMap { work() }
.doFinally { lock.unlock() } // releases on success, error, OR cancel
}
Two important details:
subscribeOn(boundedElastic)—lock.lock()can block; don't do it on a Reactor event loop thread.doFinally— runs on success, error, AND cancellation.doOnSuccesswouldn't release on failure;doOnTerminatewouldn't release on cancellation. AlwaysdoFinallyfor resource cleanup.
Kotlin coroutines — the alternative
Reactor and Kotlin coroutines are different concurrency models, both available in Spring Boot. Coroutines feel more natural for Kotlin developers because suspend functions look like normal sequential code:
suspend fun processPayment(id: String): Payment {
val txn = repo.findById(id) ?: throw NotFound()
val payment = paymentService.create(txn)
return payment
}
Under the hood, suspend functions are state machines that can pause and resume. The kotlinx.coroutines library provides Mutex (suspending lock), Channel, Flow, etc. Mixing with Reactor is possible (.awaitSingle(), asFlow()) but adds complexity.
Our codebase mostly uses Reactor, so the gotchas above apply.
Spring Boot patterns for concurrency-safe code
Spring gives you a lot of power for managing transactions, isolation, locking, and idempotency. Used well, you rarely need to write concurrency primitives by hand.
@Transactional — propagation modes
The propagation mode decides what happens when a @Transactional method calls another @Transactional method.
| Mode | If a transaction exists | If no transaction |
|---|---|---|
REQUIRED (default) | Join it | Start one |
REQUIRES_NEW | Suspend it; start a new one | Start one |
NESTED | Run as a savepoint inside the outer txn | Start one |
MANDATORY | Use it | Throw |
NEVER | Throw | Run without a transaction |
NOT_SUPPORTED | Suspend it; run without | Run without |
SUPPORTS | Join it | Run without |
For idempotency-recovery patterns (catch DataIntegrityViolationException, retry as update), REQUIRES_NEW on the recovery method is sometimes useful — the failed INSERT's transaction is rolled back, but the recovery transaction commits cleanly.
@Transactional — isolation levels
@Transactional(isolation = Isolation.SERIALIZABLE)
fun transferMoney(from: Long, to: Long, amount: BigDecimal) {
// ...
}
Available: READ_UNCOMMITTED, READ_COMMITTED (Postgres default), REPEATABLE_READ, SERIALIZABLE. Combined with retry-on-conflict, this is a clean way to handle some race conditions without explicit locks.
Optimistic locking with @Version
@Entity
class Account {
@Id var id: Long? = null
var balance: BigDecimal = BigDecimal.ZERO
@Version var version: Long = 0
}
Hibernate adds WHERE version = ? to every UPDATE. If the version doesn't match (because another transaction committed first), Hibernate throws OptimisticLockException. Catch and retry.
Good for "lost update" prevention on a known entity. Doesn't help with "two new entities racing to be the unique one" — that's the unique-constraint case.
Pessimistic locking via Spring Data
interface AccountRepository : JpaRepository<Account, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT a FROM Account a WHERE a.id = :id")
fun findByIdForUpdate(@Param("id") id: Long): Account?
}
Adds FOR UPDATE to the SELECT. The row is locked until your transaction commits. Other transactions that try to lock the same row block.
Idempotent insert pattern (the canonical shape)
@Repository
class PaymentRepository(
private val jpa: PaymentJpaRepository
) {
@Transactional
fun findOrCreate(paymentId: String, factory: () -> Payment): Payment {
val existing = jpa.findByPaymentId(paymentId)
if (existing != null) return existing
return try {
jpa.save(factory())
} catch (e: DataIntegrityViolationException) {
// race lost — somebody else inserted between our read and write
jpa.findByPaymentId(paymentId)
?: throw e // genuinely failed; not just a race
}
}
}
The schema needs a unique constraint on paymentId for this to work. Without it, both racers would succeed and you'd have duplicates.
The reactive equivalent (what's actually in our codebase, simplified):
fun findOrCreatePaymentIdempotent(paymentId: String, command: ProcessCommand): Mono<Payment> {
return paymentRepo.findByPaymentId(paymentId)
.flatMap { existing -> updatePayment(existing, command) }
.switchIfEmpty(
Mono.defer { createNewPayment(command) }
.onErrorResume(DataIntegrityViolationException::class.java) {
// re-read what won, treat as update
paymentRepo.findByPaymentId(paymentId)
.flatMap { updatePayment(it, command) }
}
)
}
Spring's LockRegistry — JVM locking with cleanup
Spring Integration provides LockRegistry implementations:
DefaultLockRegistry— JVM-only, in-memory, with cleanup of idle locksJdbcLockRegistry— distributed via a database tableRedisLockRegistry— distributed via Redis
@Bean
fun lockRegistry() = DefaultLockRegistry()
// usage:
val lock = lockRegistry.obtain("payment-link:${paymentId}")
lock.lockInterruptibly()
try {
// protected section
} finally {
lock.unlock()
}
The DefaultLockRegistry is the boring, well-tested Spring way to add a JVM-level lock without writing a ConcurrentHashMap by hand.
SQS listener concurrency in Spring Cloud AWS
@SqsListener by default runs N concurrent worker threads per replica. If your handler isn't thread-safe, you have a race even on a single replica. The number is configurable:
@SqsListener(value = ["bem-payment-received.fifo"], maxConcurrentMessages = "1")
fun handle(message: PaymentEvent) { ... }
For FIFO queues, ordering is per-MessageGroupId. AWS only delivers one message per group at a time — but if your group is shared across many logical entities (e.g. a static "payment-group"), you serialize EVERYTHING. Per-paymentId MessageGroupIds give you per-entity FIFO.
The "right" Spring stack for a duplicate-row race
Combining all of the above, the proper end-state for any "exactly one row per business key" invariant looks like:
- DB unique constraint on the business key.
@Transactionalon the operation (to define commit boundaries).- Catch
DataIntegrityViolationException, recover by re-reading the winning row. - Optionally: per-key
MessageGroupIdupstream so SQS FIFO serializes naturally and the recovery path almost never fires.
That's the textbook combination — minimal coordination, maximum correctness. A lock at the application layer is the right call only when one of these layers can't (yet) carry the invariant.
Worked example: duplicate-row race from concurrent webhooks
A common shape that ties everything from the previous tabs together. Imagine an e-commerce service that receives two webhooks per payment from an upstream processor: one carrying the basic confirmation and one carrying the card details. The service must produce exactly one ledger entry per payment.
1. The pipeline
Two webhooks for the same logical payment land within milliseconds of each other on a shared queue. The queue dispatches them to two worker threads. Both workers run the same handler, which: looks up the existing ledger entry, and if none exists, inserts one.
Two webhook events for the same payment fan out to two workers. Both reach the ledger-creation step nearly simultaneously.
2. The race in code
// "find or create" — TOCTOU shape
findByPaymentId(paymentId)
.filter { it.matches(paymentId) } // CHECK
.next()
.flatMap { existing -> /* reuse */ }
.switchIfEmpty(
Mono.defer { createNewLedgerEntry(...) } // ACT
)
Classic TOCTOU. Worker A reads empty, Worker B reads empty (under READ COMMITTED, B can't see A's uncommitted INSERT), both proceed to createNewLedgerEntry, both INSERT. Two ledger rows for one payment.
3. Visualizing it
Three lanes — Worker A on top, the actual committed database state in the middle, Worker B on the bottom. Watch the middle lane — what each worker reads is whatever the middle lane contains at that moment.
Each worker reads the actual committed DB state — not each other's local state. When B reads at t=2, A hasn't committed yet, so B sees empty and decides to insert. With the lock, B can't even read until A finishes.
4. Three ways to fix it (from most to least preferable)
Option A — Database unique constraint + recovery
Express the invariant where it lives. The database refuses the duplicate INSERT; application code catches the violation and re-reads the winner.
CREATE UNIQUE INDEX uq_ledger_per_payment
ON ledger_entries (payment_id) WHERE payment_id IS NOT NULL;return repo.save(newEntry)
.onErrorResume(DataIntegrityViolationException::class.java) {
repo.findByPaymentId(paymentId)
}
Pros: the database enforces the invariant — no application code path can violate it. Microsecond cost. Self-documenting in the schema.
Cons: requires the table to be free of existing duplicates (a backfill / cleanup may be a prerequisite).
Option B — JVM lock keyed by payment id
A ConcurrentHashMap<String, ReentrantLock> serializes threads in one JVM. Sufficient when all events for a given key reach the same JVM (single-replica deployment, or FIFO with per-key MessageGroupId).
private val perPaymentLocks = ConcurrentHashMap<String, ReentrantLock>()
private fun <T> withPaymentLock(paymentId: String, work: () -> Mono<T>): Mono<T> {
val lock = perPaymentLocks.computeIfAbsent(paymentId) { ReentrantLock() }
return Mono.fromCallable { lock.lockInterruptibly(); true }
.subscribeOn(Schedulers.boundedElastic())
.flatMap { work() }
.doFinally { lock.unlock() }
}
Pros: zero new infrastructure, nanosecond latency, well-understood semantics.
Cons: only works within one JVM. Multi-replica without per-key routing → silent gap.
Option C — Distributed lock keyed by payment id
Reach for this when (a) you really do have multiple replicas processing the same key in parallel, AND (b) a database constraint isn't viable. Costs: SNS/Redis/etc. round-trip per acquire (~tens of ms), more moving parts, more failure modes.
5. Decision summary
The right call almost always lives in this order:
- Can the database enforce it via a unique constraint? Do that.
- If not (yet), is it sufficient to serialize within one JVM? JVM lock.
- If you genuinely need cross-replica coordination of a side-effect that isn't a row? Distributed lock.
Skipping ahead to the heaviest tool because "it'll definitely work" is a recurring pattern that buys complexity without buying correctness.
6. Why the lock fix actually works
- The lock wraps the whole "find-or-create" flow — including the read AND the eventual INSERT.
- The lock releases via Reactor's
doFinallyAFTER the innerMonocompletes — which is after the JPA flush + commit. - Worker B can't acquire until Worker A releases. By that time A's row is committed and visible.
- B's subsequent read sees the row, takes the "already exists" path, no INSERT.
Lessons to internalize
Ten principles distilled from real concurrency bugs. They generalize across stacks; the specifics here lean Kotlin/Spring/Postgres because that's the canonical example.
1. Express invariants where they live.
Data invariants belong in the database (constraints). Process invariants belong in code (locks, guards, state machines). Putting a data invariant in code is fragile — every code path has to remember the rule. Putting a process invariant in the database doesn't usually work — the database doesn't know about your processes.
"At most one row per business key" is a data invariant. It belongs in a unique constraint, not in if (!exists) insert guards scattered across the codebase.
2. Idempotency is per-step, not propagated.
Hardening one step of a pipeline doesn't magically harden downstream steps. A common failure mode: "step 1 catches DataIntegrityViolation and recovers, so we're idempotent" — but step 2 has its own check-then-act that has no protection. Audit every state-changing step independently.
3. "It worked for years" is not evidence of correctness.
Race conditions are timing-dependent. The same code can fire 0.001% of the time for years, then 50% of the time after an unrelated infrastructure change — a framework upgrade that increased listener concurrency, an autoscaling event that doubled replica count, an upstream change in event-batching behavior. Patient bugs are real. Years of "no incidents" tells you about luck, not correctness.
4. Lock granularity matters more than lock type.
A perfectly-implemented lock at the wrong granularity is wrong. Too coarse over-serializes and kills throughput. Too fine misses part of the race. The correct granularity is "exactly the resource being raced for" — usually whatever business identifier the racing operations agree on (a customer id, a payment id, an order id).
5. Decide what you need from a lock before picking one.
JVM lock if you need cross-thread within one process. Postgres advisory or distributed lock if you need cross-process. Unique constraint if the invariant is on data and you can have a constraint. Don't pick the heaviest tool because "it'll definitely work" — picking too heavy has costs (latency, infrastructure, complexity, configuration).
6. Read-committed is not "no isolation."
People sometimes say "we get races because we use read-committed." That's misleading. Read-committed prevents dirty reads — a real protection. It doesn't prevent TOCTOU races between SELECT and INSERT, because those are designed to be fast (no row locking on read). The fix is application-level, not isolation-level — usually a unique constraint or a lock.
7. Test races deterministically when you can; with iterations when you can't.
Reproducing a race deterministically in a test is genuinely hard. Natural concurrency in tests is timing-dependent — sometimes the bug fires, sometimes it doesn't. Two reasonable approaches: (a) inject a latch or spy at the exact contention point so both racers stall before either commits; (b) loop the scenario 5–10× per test run so any single iteration that hits the race fails the whole test. Less elegant than a single deterministic assertion, but it catches regressions reliably and rejects flaky-fix attempts.
8. Production data is the truth. Don't argue with it.
It's tempting to say "but the queue is FIFO" or "but our deployment is single-replica, so the race shouldn't be possible." If production shows duplicate rows, the race IS possible — your model of the system is incomplete. Reconcile your model with the data, not the other way around. There's always a delivery semantic, an autoscaling rule, or a retry path you didn't account for.
9. Be honest about what your test does and doesn't reproduce.
Integration tests for race conditions often reproduce a related variant of the race rather than the exact production variant — different schema constraints, different in-test scheduler, different connection-pool semantics. The fix may still be correct (it serializes the whole flow upstream of where the variants diverge), but the test only directly demonstrates one of them. PR descriptions and code comments should be honest about this.
10. "Workaround now, proper fix next sprint" is a valid plan — when you say so explicitly.
Sometimes the proper fix (e.g., a unique constraint) is blocked by prerequisite work (e.g., cleaning up historical duplicates). Shipping a temporary fix (e.g., a lock) that stops the bleed is fine — as long as you label it clearly: this is interim, the proper fix is X, and when X is unblocked we will replace this. Knowing the difference between a workaround and the proper fix — and being explicit about which is which — is half of senior engineering.